- Simple AWS
- Posts
- Chaos Engineering: Using AWS Fault Injection Simulator
Chaos Engineering: Using AWS Fault Injection Simulator
Let's test what happens when an instance or DB fails
Guille Ojeda
August 04, 2023
You wrote an app that runs in an EC2 instance and connects to a Postgres database. You've been reading Simple AWS for a while, so you know that if you want the app to be highly available you'll need to deploy it in an Auto Scaling Group with a minimum of 2 instances, and use Aurora with a replica (you could use RDS, ECS, Aurora Serverless, etc, but let's go with this). You deployed it like that, but now you'd like to actually test that it keeps working if an EC2 instance or the main Aurora instance fails.
What is Chaos Engineering?
From Wikipedia, Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system's capability to withstand turbulent conditions in production. Translation: It's the discipline of breaking prod in a controlled way to understand how it breaks, so when it breaks in an uncontrolled way it doesn't cause a nuclear explosion.
Though chaos engineering can be traced back at least to 2003, Netflix popularized it in 2011 with its famous Chaos Monkey, a bot designed to continuously terminate random production servers. But Chaos Engineering is not just randomly breaking stuff, it's about science!
Chaos Engineering can actually be summed up with these statements that I've collected over the years (none of them are originally mine):
Everything fails, all the time.
The degree to which you know how a system behaves is the degree to which you've tested it.
Testing specifies acceptable behavior in the face of known data, while monitoring confirms acceptable behavior in the face of unknown user data.
Ways in which things go right are special cases of the ways in which things go wrong.
Resilience is a functional requirement: It's about how the system behaves under certain conditions.
Hope is not a strategy.
Doing Chaos Engineering right is actually pretty hard. On one hand, you need the tech knowledge of how things can break. On the other hand, you need the scientific mindset of bringing up assumptions, coming up with theories, designing experiments to disprove those theories, running those experiments, analyzing the results and drawing conclusions.
I wrote a much longer explanation of it on my article Chaos Engineering on AWS. I won't replicate it here, and instead I'll keep this practical.
Just one more piece of wisdom: Before you do this in prod, do it in dev/test/staging. Basically, test the experiment.
Using AWS Fault Injection Simulator to simulate a failure
Here's the initial setup, and you can deploy it here:
Step by step instructions to configure Fault Injection Simulator
Step 0: Review the setup, make assumptions and design chaos engineering experiments
The setup is an Auto Scaling Group with a minimum of 2 EC2 instances sitting behind an Application Load Balancer, and they connect to the Writer Endpoint of an Aurora cluster with 2 instances: Main and Replica.

Assumption 1: If one instance fails while under load, the other instance can serve all the users while a replacement instance is launched.
Assumption 2: If the Main instance in the Aurora cluster fails, failover to the Replica instance happens automatically and with no service disruption.
Experiment 1: Simulate load with 2 instances and terminate one instance.
Expected result: The other instance handles all the requests without failing, a new instance is launched to replace the terminated one, the new instance goes online and starts handling traffic automatically (no manual intervention), and no requests result in errors.Experiment 2: Simulate load and terminate the Main Aurora instance.
Expected result: Failover happens automatically and no requests result in errors.
We already know what happens if an instance fails in an auto-scaling group behind a load balancer, right? And we know what happens if an instance fails in an Aurora cluster. Well, let's take what we "know" and write it down as clearly and precisely as possible. Those are our hypotheses. Now it's time to prove or disprove them.
Step 1: Set up Experiment 1 - Terminating an EC2 Instance
We're going to configure the actions that we want to happen. It's pretty simple in this case: Find all EC2 instances tagged Name: SimpleAWS39, and terminate 50% of them.
Go to the Fault Injection Simulator console and click "Create experiment template"
For Description, enter "Terminate 1 EC2 instance"
For Name, enter "Experiment 1"
In the Actions section, click Add Action
For Name, enter "TerminateEC2Instances"
Open the dropdown that says Select action type, start typing "EC2" and select aws:ec2:terminate-instances
In the Action you just created, click Save
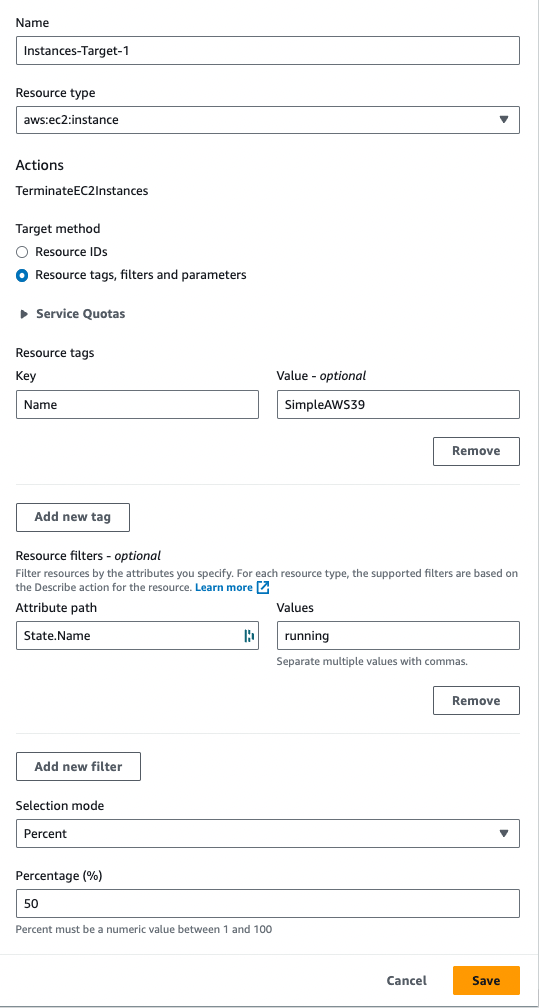
In the Targets section, click the Edit button next to Instances-Target-1 (aws:ec2:instance)
Change Target method to "Resource tags, filters and parameters"
Click Add new tag
For Key, enter "Name"
For Value, enter "SimpleAWS39"
Click Add new filter
For Attribute path, enter "State.Name"
For Values, enter "running"
Under Selection mode, open the dropdown and select Percent
For Percentage (%), enter 50
Click Save
Under Service Access, open the dropdown for IAMRole and select FISExperimentRole
Under Logs, check Send to CloudWatch Logs
Click Browse
Find the log group named simpleaws39/fis-logs, select it and click Choose
Click Create experiment template
In the popup that appears enter "create" and click Create experiment template
Step 2: Generate Load on the EC2 Instances
If a tree falls down and there's no one around to hear it, does it make a sound? I'm not sure about trees, but if a server falls down and there's no users, it doesn't make a sound at all. So, let's get some users!
Go to the CloudFormation console
In the Outputs tab, copy the URL of the load balancer
Open CloudShell
Run the following command, replacing
[URL_OF_THE_LOAD_BALANCER]with the URL you just copied:
export URL=[URL_OF_THE_LOAD_BALANCER]Run the following command:
printf '#!/bin/bash\necho "Generating load on ${URL}..."\nwhile true; do\n STATUS=$(curl -s -o /dev/null -w "%%{http_code}" "${URL}/")\n if [ "$STATUS" -ne 200 ]; then\n echo "Received response code $STATUS"\n fi\ndone\n' > load_test.sh && chmod +x load_test.shRun
./load_test.shto start it, press Ctrl + C (even on Mac) to stop.
Step 3: Monitor the Responses From EC2
Let's see what it looks like when the system is running well. In a real system you should have a better dashboard, and a real experiment includes a way to view the metrics that our assumptions depend on. To keep it simple, we're just using the default Monitor view here.
Open the EC2 Load Balancers Console
Select your load balancer
Click on the Monitoring tab
Click on the Custom button and on the same row of Minutes click on the button that says "15"
Scroll down and review the metrics. Keep an eye on HTTP 2XX
Step 4: Launch Experiment 1 - Terminating an EC2 Instance
Now that we've seen it working well, let's do like Oppenheimer!
Go back to the FIS Console
Select the template you created in Step 1
Click Start experiment
Once again, click Start experiment
Type "start" and again click Start experiment
Step 5: Analyze the results of the experiment
We've ran the experiment, now let's view the results. We'll analyze your metrics (ops view), and from the users' point of view (users view).
Go back to the EC2 Load Balancers Console tab
Check the metric HTTP 2XX. It should have been reduced by half
Go back to the tab where you have CloudShell open
Check whether you see any messages like "Received response code 504"
Step 6: Set up Experiment 2 - Terminate the Main Aurora Instance
We'll do the same thing as in Step 1, but now we're setting up the failover of the Aurora cluster.
Go back to the Fault Injection Simulator console and click "Create experiment template"
For Description, enter "Aurora Failover"
For Name, enter "Experiment 2"
In the Actions section, click Add Action
For Name, enter "FailoverAuroraCluster"
Open the dropdown that says Select action type, start typing "RDS" and select aws:rds:failover-db-cluster
In the Action you just created, click Save
In the Targets section, click the Edit button next to Clusters-Target-1 (aws:rds:cluster)
Open the dropdown under Resource IDs
Select the cluster created by the Initial setup
Click Save
Under Service Access, open the dropdown for IAMRole and select FISExperimentRole
Under Logs, check Send to CloudWatch Logs
Click Browse
Find the log group named simpleaws39/fis-logs, select it and click Choose
Click Create experiment template
In the popup that appears enter "create" and click Create experiment template
Fun fact: the request rds:FailoverDBCluster is globally scoped, so if you have an SCP blocking some regions with a list of global permissions that are excepted from the Deny (e.g. route53:*), you need to add rds:FailoverDBCluster. I wasted an hour on this.
Step 7: View the current state of the Aurora cluster
Let's see what the database looks like before the experiment.
Go to the RDS Console
Write down or memorize which instance is the Reader instance and which is the Writer instance

Step 8: Launch Experiment 2 - Terminate the Main Aurora Instance
Time to run Experiment 2. Cross your fingers! 🤞 (kidding)
Go back to the FIS Console
Select the template you created in Step 6
Click Start experiment
Once again, click Start experiment
Type "start" and again click Start experiment
Step 9: View the results of the experiment
Now let's check if something changed in the database. The failover should happen, alright. But let's also check the ops view (metrics) and the user view (the output in the simulated users) to see if anything failed.
Go back to the RDS Console
Check whether the instances switched roles

Go back to the EC2 Load Balancers Console tab
Check the metric HTTP 2XX, it should have gone down. Also check the HTTP 5XX one.
Go back to the tab where you have CloudShell open
Check whether you see any messages like "Received response code 500"
Step 10: Kill the load-generating script
Either go back to the tab where you opened CloudShell, or open CloudShell in any tab.
Press Control + C (on every OS, even Mac).
Make sure the script stops. Press it again if you have to.
Best Practices for Chaos Engineering with AWS FIS
Operational Excellence
Implement a Controlled Testing Environment: Before running chaos tests on your production system, build a controlled environment that mirrors your production setup. Get all the information you can from there, and only then go break production.
Document and Automate Experiments: Maintain clear and up to date documentation of your experiments, and automate them using templates (like we did in this issue).
Monitor and Alert During Experiments: Use CloudWatch to monitor the system's behavior during experiments. Set up alerts, and set up stop conditions for the experiments based on those alerts. Basically, don't break prod more than you have to.
Security
Apply Permissions Carefully for FIS: Assign least privilege permissions to the IAM roles used by FIS, and to the users that have access to FIS.
Reliability
Test Various Failure Scenarios: Use FIS to test different types of failures. Design for failure, and test for it.
Use Alarms and Automate Recovery: Set up CloudWatch alarms to trigger automatic recovery actions. This can include automatically restarting failed EC2 instances or restoring database backups.
Performance Efficiency
Evaluate Performance Metrics Post-Failure: After running an experiment, evaluate performance metrics to understand how the failure impacted the system's behavior.
Scale Testing in Phases: Start with smaller, less severe failure simulations, and gradually increase the complexity and intensity of your experiments. This helps you better understand at which point each failure occurs, instead of the obvious and useless conclusion "with a trillion users everything fails".
Cost Optimization
Monitor Costs Associated with Experiments: Use Cost Explorer to monitor the costs associated with your experiments. This includes the costs of additional EC2 instances or other resources that may be required during testing.
Resources
Gremlin is a Failure as a Service tool that helps you run chaos engineering experiments really easily.

Did you like this issue? |
Reply