Anyone will tell you high availability and scalability are essential aspects of building robust and reliable applications in the cloud. Even ChatGPT knows they're important (it actually wrote that first sentence). But what are they really, and why do we care about them? And most importantly, what are the costs of high availability and scalability, and when should we avoid them?
If you're reading this, I'd expect you to have a general idea of what the terms mean, and know a couple of ways to achieve them in AWS (if you don't, I wrote a book about it and created a video course). In this article I'll dive deep into the concepts, from a technical perspective and with a critic eye.
Understanding High Availability in the Context of AWS
In general, high availability means the ability of a system to continue functioning with little or no interruption when a component fails. AWS gets a little more specific: the ability of a system to continue functioning with little or no interruption when an Availability Zone fails. In practice the distinction doesn't matter much; in both cases you need to avoid having a single point of failure in any aspect of your infrastructure, though if you're using the AWS definition you'll have to put the copies in different Availability Zones.
In case you don't know, Availability Zones are essentially data centers (technically they're one or more data centers grouped together). A data center failing is always a risk, and with cloud providers it's usually easy to mitigate. That's why AWS puts emphasis on that and recommends you deploy your resources in multiple AZs.
Regional vs Zonal Services in AWS
When you deploy a resource like an EC2 instance, behind the scenes it's only one instance in a single physical server. That's a Zonal resource, since it resides in a single Availability Zone. Some other logical resources are backed by multiple physical devices, but even then you might be dealing with a zonal resource. For example, EBS volumes are virtual disks backed by a set of multiple physical disks in a RAID configuration, but they're still Zonal.
Regional resources are logical resources that are backed by multiple physical devices in multiple Availability Zones, meaning they're highly available by design. For example, an Application Load Balancer is implemented using multiple EC2 instances in different availability zones, which is why you're required to choose subnets in more than one AZ when you create one. S3 buckets are another great example: You just create a bucket and know that behind the scenes the data is "replicated 6 times across at least 3 Availability Zones" (from the docs).
If you want your architecture to be highly available, you need every single element to be highly available. Using regional services makes that much easier, obviously. If you use zonal services, you'll need to implement high availability yourself, for example by creating an Auto Scaling Group in multiple AZs for your EC2 instances.
Three things to keep in mind:
Most managed services are regional, but not all. RDS instances, for example, are zonal
I talk about regional and zonal "services", but it's actually the resources that are regional or zonal. Security Groups, for example, are a resource that belongs to the EC2 service, and they're regional
Don't assume things are regional. Check!
High Availability and Fault Tolerance: Not The Same
High availability means the ability of a system to continue functioning with little or no interruption when a component fails. Fault tolerance means the same, but with absolutely no interruption. If you want your system to be highly available, being able to recover quickly is enough (nobody agrees on exactly how quickly!). For fault tolerance, it isn't enough that you can spin up a backup resource in under a minute, it needs to be already available.
Let's talk about it with an example. Suppose your web application needs 2 virtual servers to serve the current traffic (let's assume traffic is constant). If you have 2 servers and can spin one up in 2 minutes, then your application is highly available: If one of them fails your users are impacted, but you can recover "quickly". However, it isn't fault tolerant! If you want it to be fault tolerant you need to keep 3 servers live at any given point, so if one of them fails traffic can fail over to the other two and users won't see any service interruption.
When talking about these topics in AWS we need to also consider Availability Zones. If you want a highly available application you'll want those 2 servers distributed across 2 availability zones, so you can recover quickly if one of those AZs fails. If you want it to be fault tolerant, you'll want 2 servers in each of those 2 availability zones, or even better (cheaper!), one server in each of three availability zones.

Highly Available architecture and Fault Tolerant architecture
Choosing Between High Availability and Fault Tolerance
Choosing between high availability and fault tolerance is only relevant in AWS certification exams. The right question is: How much does downtime cost me? In the above example for high availability if one instance fails the system stops working for half your users. You can completely eliminate that downtime by adding a third instance, which increases your compute costs by 50%. The question is whether paying that additional money reduces your expected lost revenue by a higher amount than what it costs you. Naturally, this depends on the system. 2 minutes of downtime on your blog means nothing, on your E-commerce you might lose $5, on your system to control a nuclear reactor you might blow up half a country. I already discussed this a bit when I wrote about Disaster Recovery and Business Continuity on AWS.
There are a few additional considerations, for example the possibility that if you lose half your instances then suddenly doubling the traffic to the other half will overload them, and cause a cascading failure. Overall, you need to understand how your system fails. Thinking really hard is good! Testing things is even better, and you can do so with Chaos Engineering.
Understanding Scalability
Scalability is a system's ability to dynamically change the capacity to adapt to variations in traffic. It comes in two flavors: Vertical scalability means changing existing resources for larger ones (scaling up) when traffic increases, and for smaller ones (scaling down) when traffic decreases. Horizontal scalability means adding more resources (scaling out) when there are high traffic demands and removing resources (scaling in) when demands are lower.
Scaling vertically is usually harder and requires downtime, so we always prefer horizontal scalability. There are a few requirements for horizontal scalability, the most important one being stateless resources, but we also need stateless resources for high availability, so it's not like we're introducing something new. We'll discuss stateless resources in another section further down in this article.
Overall, the idea of scalability is to keep your actual capacity as close as possible to what you need to handle the current traffic. That way you reduce unused capacity (i.e. resources which you're paying for but not using). When traffic goes up you increase capacity to be able to serve it, and when traffic goes down you remove that excess capacity so you don't pay for something you don't need.

Example of Benefits of Auto Scaling
In theory you keep the exact capacity that you need right now, and when that need changes your capacity changes instantly to match it. In practice you'll find that capacity doesn't change instantly, and you need to keep a buffer. The key concept here is scaling speed.
Scaling Speed
Scaling speed in the time between when traffic changes and when your capacity changes to match it. It depends on two factors:
Time to detect: The time between when you detect the need to scale. Traffic fluctuates all the time, so this is usually handled with an upper and lower thresholds. When traffic crosses a threshold, you decide you need to update those thresholds (and your capacity, obviously).
Time to scale: The time between when you decide you need to change your capacity and when that change is made effective.
Reducing time to detect means making your scaling more sensitive, which is good for very spiky traffic, but it also means you'll get more false positives: small spikes in traffic that don't last long enough to make scaling worth it, and which don't accurately predict traffic in the near future (a couple of minutes).
What we typically focus on is time to scale. The faster we can launch resources, the less excess capacity we need to keep to handle traffic increases until we're ready to add that capacity. In fact, this is the entire premise of cloud computing!
No matter what anyone says, traditional data centers are scalable: You detect the traffic increase, go buy a server, install it and configure it. Sure, it takes a couple of days to a couple of months, but you can scale. With "the cloud" you increase your capacity in minutes, so you don't need to keep as much extra capacity to handle the traffic increase until you're ready to add more servers. Of course, within "the cloud" we can optimize this further if needed (for example using Lambda functions vs EC2 instances), but the idea is the same.
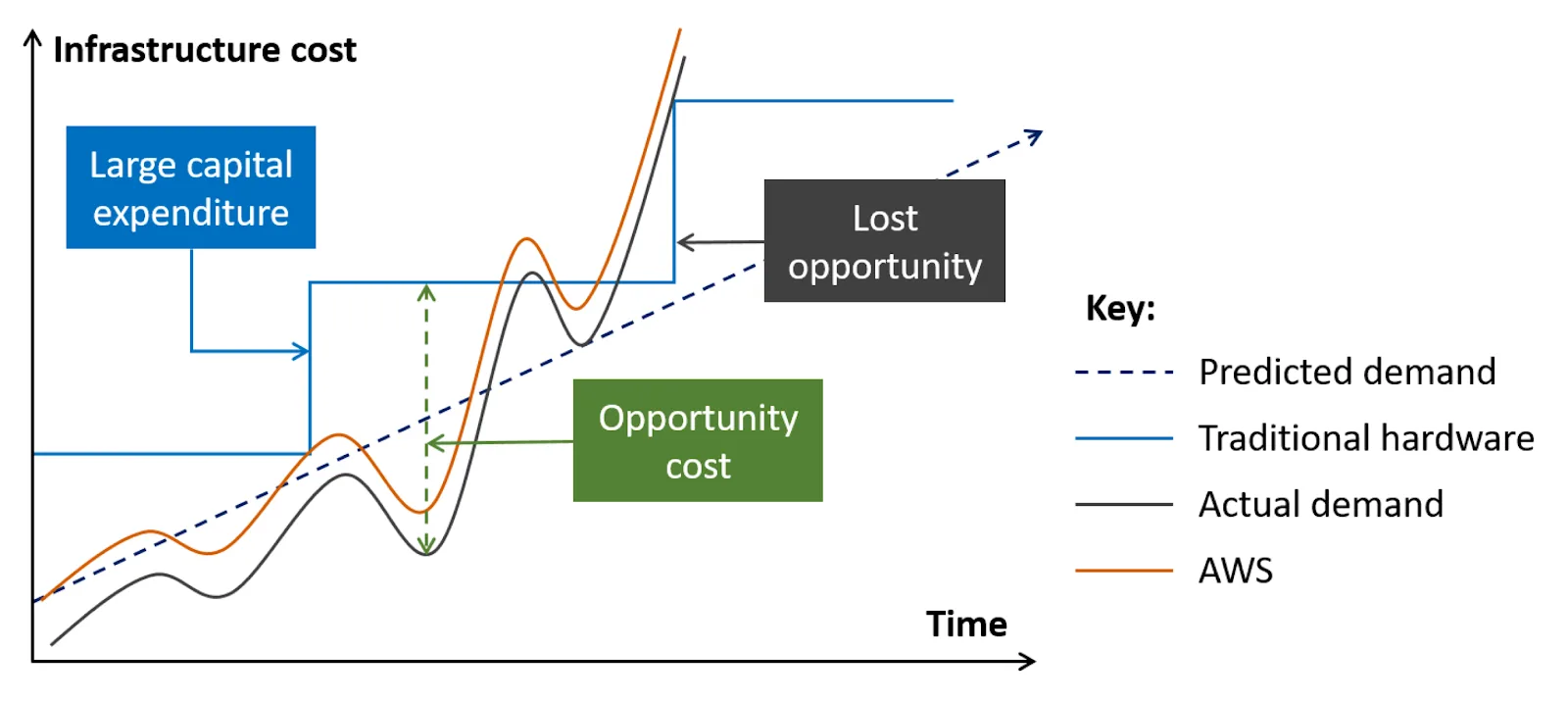
Typical image of scaling in the cloud
It's important to understand that, since scaling isn't instantaneous, we don't scale to handle our current traffic. Instead, we use current traffic and its variations to predict future traffic (in the next couple of minutes) and adjust our capacity to match that future traffic.
Increasing and Decreasing Capacity
Scaling can be up/out (increase capacity) or down/in (decrease capacity). Both are important, but they require different approaches, because of their consequences.
We scale out so we can serve our users. If we fail to scale out, or scale out too slowly, some users will see errors. That means some lost revenue (presumably you make money when users use your website), but it also means a loss of customer satisfaction and a hit to your reputation. For that reason, we prefer to err on the side of the users, and keep some extra capacity available to give us time to react (scale). For example, it's typical to target a utilization below 70% for EC2 instances, and when it grows beyond 70% we launch a new instance (scale out).
It's important to note that we might have spikes in traffic that are just anomalies and don't accurately predict future traffic. For that reason we don't actually scale out when a metric like usage is above a threshold like 70%. Instead, we scale out when that metric is above that threshold for a certain period of time, for example for 3 minutes. Reducing this scaling period makes our scaling faster, but it also means we might erroneously scale based on false positives: spikes in traffic that don't actually predict a sustained increase in traffic, but we didn't wait long enough to confirm that. This isn't as bad as it sounds though: at worst, we'll have a bit more resources than we need and pay a bit more, but at least our users won't be impacted.
Scaling in, on the other hand, isn't about users. Users don't care if we have one or a million EC2 instances standing by, or if our utilization is at 60% or 1%; their requests will get served just the same either way. The only reason we scale in is to reduce costs. Which is obviously very important! But it's a lot easier to quantify than "your reputation".
Just like we have spikes up in traffic, we can also have spikes down: temporary reductions in traffic that don't predict a sustained reduction. We need to be especially careful with these though, because if we scale down when we didn't need to we might end up with less capacity than what can handle the actual traffic, and users will be impacted.
My advice: Scale out eagerly, scale in conservatively. If you scale out too soon, the worst thing that can happen is that you have one more instance than you actually need. However, if you don't scale out soon enough your users will be impacted. On the contrary, if you scale in too soon you'll end up removing capacity that you actually need, and users will be impacted. Scaling in too late, on the contrary, just means you keep paying for an extra instance for a few minutes more. So, to err on the side of minimizing user impact, scale out eagerly and scale in conservatively.
Stateful and Stateless Applications (actually, resources)
State is data that is used for more than one request. For example the contents of a shopping cart, a session, or overall your entire database. You obviously need to store this somewhere! But you can't duplicate it across multiple places that change independently, or state will diverge and you'll get things like two users with the same email address.
Stateful Applications will store state inside "the application", while Stateless Applications store state outside "the application". You want your "applications" to be stateless, so you can have multiple copies of it (high availability) and create and destroy copies freely (scaling out and in) without risking duplicating or losing data.
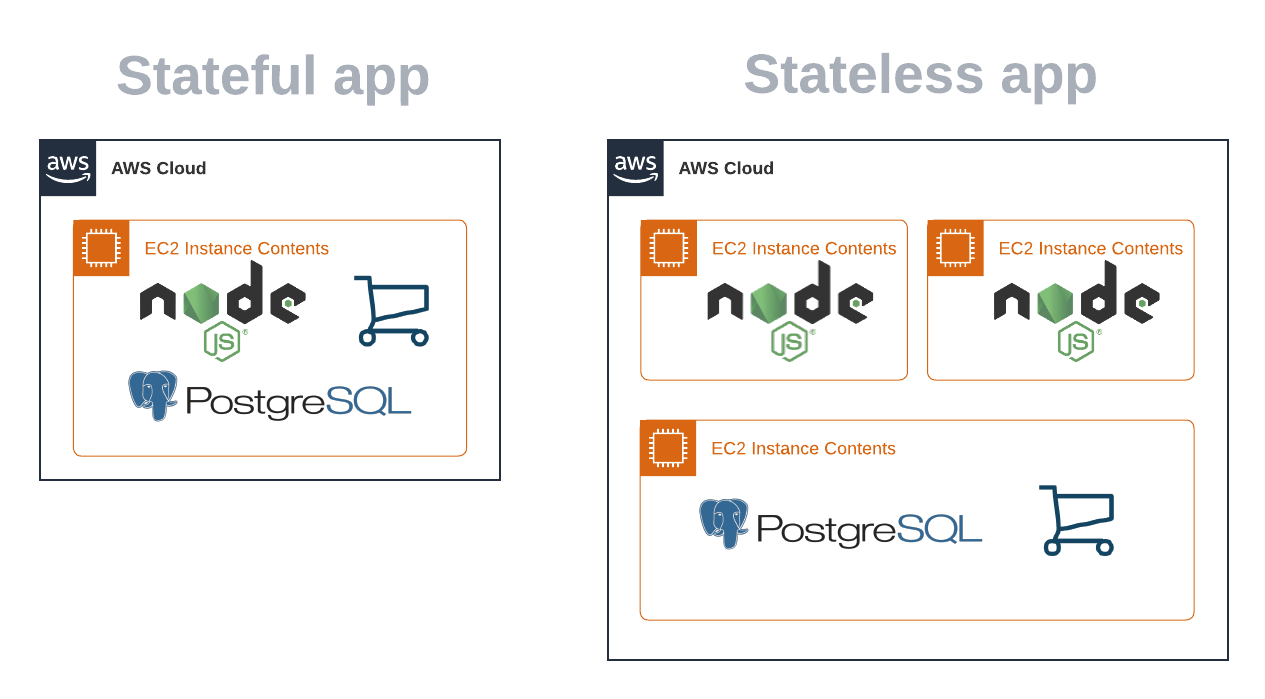
Stateful app vs Stateless app
When I say "application" here, what I actually mean is deployment unit. For example, your EC2 application instance (i.e. your web server). If you store your database inside your EC2 instance, you can't create a second EC2 instance or you'll be duplicating the data on places that change independently, and you can't scale in to 0 instances or you'll be deleting the data.
The terms Stateful Application and Stateless Application are industry standards, which is why I use them here. Besides, we can't just talk about stateless resources, since we can't make every resource stateless; we need to store our state somewhere! However, viewing this from a different angle it's hard to argue that your database, even if stored separately (e.g. in an AWS RDS database instance instance), isn't part of your application. So, whenever you read Stateless Application, understand that "application" means the deployment unit for the application code.
Removing State From A Deployment Unit
You need to store your state somewhere other than where you run your application code. With some experience you'll do this sort of automatically when you're designing the application, but when you're starting out you might want to think this step by step, at least conceptually. Additionally, if you ever work as a cloud consultant, a big part of it is Application Modernization, which means fixing bad cloud architectures, which many times involves making apps scalable, which means making it stateless.
The key to removing state is understanding where that information should be stored. These are the types of state you'll typically find, the storage requirements they have, and where you could put them in AWS:
Transaction data: These are your main transactions, like sales, and everything that you need to make them happen (e.g. product catalog). You want to store these in a durable and queryable place. If you choose a SQL database, Amazon Relational Database Service (RDS) is the way to go, with a failover replica for high availability. You should also consider DynamoDB.
User data: This is also critical, but sometimes it's managed separately with an identity provider like Cognito.
Session data (including shopping carts): This data should last a few hours to a few days, and it's typically only queried by ID. You'll want to store this somewhere where you can query by ID very cheap and fast, and where you can easily expire it when needed (important for security reasons). DynamoDB and ElastiCache are great choices within AWS.
Configuration data: This is data that your application needs to read to function properly, like a database connection string. If the application doesn't update this and it isn't sensitive data, you can store the config files in the code and deploy them to your instances with application updates. If one instance can change the data and other instances need to view the change you can either use a shared file system like EFS or S3, set up a DynamoDB table for this, or use a configuration manager like AWS Systems Manager. If the data needs to be secret (e.g. your database password), make sure to use an encrypted store or manager, like Secrets Manager, and that permissions are properly set up.
Data Streams: This is data that you need to process before storing, like click streams or sensor data. You'll want to store it in a transient storage that allows easy access and event-driven integrations, like Kinesis Data Streams, Amazon SNS, or even DynamoDB. After processing it you might discard it or store it somewhere cheap like Amazon S3.
If you're moving actual data of systems that are in production, in addition to thinking about the end state (i.e. how things will look like after you're done) you also need to plan how to execute those changes. If you're moving a database from an installation in the instance to an Amazon Aurora DB cluster you'll need to create a maintenance window and at least pause DB writes. Other data types are usually easier, and you can do double writes (i.e. write to the old and the new storage) until you've changed the read source and are confident that things work well.
Making Your Architecture Highly Available and Scalable
Once you understand high availability and scalability, and once your application is stateless, making your cloud architecture highly available and scalable is just a matter of understanding the different AWS services.
High Availability and Scalability for AWS Compute Services
Here are your basic options for a highly available and scalable compute layer in AWS:
Amazon EC2: Create an Auto Scaling Group that spans multiple Availability Zones, and add an Elastic Load Balancer in front of it.
Containers: Either use Amazon Elastic Container Service (ECS) or Elastic Kubernetes Service (EKS). You can use an Auto Scaling Group or AWS Fargate as a capacity provider.
Serverless: AWS Lambda is highly available and scalable by default. You can fine tune a few things like reserved capacity.
The order isn't random. As you go from top to bottom you'll get a faster scaling speed (which lets you keep less capacity in reserve), you'll get more done by AWS (meaning less work for you, and less $$$ spent on engineering hours), and you'll also pay more per compute unit.
For new applications I recommend either a fully serverless approach with a serverless database, or containers on ECS using Fargate. For apps already running in EC2 it's typically easier to add an auto scaling group than to re-architect it, but sometimes re-architecting is worth it.
High Availability and Scalability for AWS Database Services
All AWS database services can be made highly available and scalable, so that shouldn't be the main factor when choosing your database service. Here's a list of the most common AWS DB services and how they handle high availability and scalability:
Amazon RDS: It's made highly available by adding failover replicas. It can't scale horizontally, only vertically, which requires a few minutes of downtime but is pretty easy to do: stop the instance, change the size, start the instance.
Amazon Aurora: RDS's cooler cousin has replicas that act as both read and failover, meaning that your existing aurora replica that you created for high availability doesn't need to be sitting idle. Additionally, you can set up an Aurora Global Database for cross-region availability. As for scalability, it's only vertical, just like for RDS, but you can opt for Aurora Serverless, where you scale the compute nodes very similarly to an Auto Scaling Group (i.e. not really serverless, but horizontally scalable, which is a big win).
Amazon DynamoDB: It's highly available by design. It can scale in two modes: Provisioned lets you set rules to scale read and write capacity, On Demand handles everything automagically and you just pay per request (like S3). I wrote a great article about how DynamoDB scales.
Amazon ElastiCache: It scales horizontally with multiple nodes, both for Redis and Memcached. Memcached is single-AZ, meaning it can't be made highly available according to AWS's definition.
As you can see, except for Memcached they can all be made highly available. The factor that should influence your decision is how much that high availability costs: 2x for RDS, $0 extra for DynamoDB, etc.
High Availability and Scalability for AWS Storage Services
Just like for databases, choosing the right storage option depends on understanding the different services. The difference is that you don't make a storage highly available and scalable via configuration, you just pick a different service. Here's how each service behaves:
Amazon EBS: EBS is a block storage service. EBS volumes are zonal, and you can't make them highly available. You can scale them vertically both in size and performance (for modern volume types these scale independently), but this is something you do rather infrequently.
Amazon EFS and Amazon FSx: Managed file storage solutions that are highly available by default. Storage scales automatically, and performance depends on the different throughput modes.
Amazon S3: Scalable object storage that scales to infinity automatically, and you don't control performance. It's object-based though, not file-based.
AWS Systems Manager and AWS Secrets Manager: Not storage services, but you usually use them to store configurations. They are small enough that performance and storage don't matter (and if you reach the limits, you're either doing something very wrong or dealing with a very interesting problem!)
When is High Availability Not Worth It?
Generally, we want highly available systems because it's easy and cheap to achieve, and ensuring a good experience for users is worth the cost. However, not every system is cheap and easy to make highly available and scalable.
Obviously, non-production systems don't care about reputation or users, so we don't need high availability there. For production systems (the interesting ones) the decision comes down to how much it costs us to make our systems highly available. Here are a few examples:
If you only have one EC2 instance, making it highly available means adding a second EC2 instance (possibly halving the size of both) and an Application Load Balancer. More importantly, it means making your app stateless (I bet it isn't!). Usually a lot of work.
If you have several EC2 instances with elastic load balancing, spreading them across multiple AZs is trivial in most cases. The exception is high performance computing requirements where the inter-AZ latency might play a big role.
If you have a stateless, containerized application, deploying it to ECS is trivial.
If you have a relational database, making it highly available means adding a failover replica, which doubles your database costs.
If you're using DynamoDB, you're already highly available, even if you didn't know it.
Same if you're using Lambda!
When is Scalability Not Worth It?
It's only not worth it if you're 100% certain your traffic will stay within certain well-defined parameters. That sounds like an impossible situation, but in some cases you might want to create that situation. For example, if you have a component deployed in AWS Lambda, which scales really fast, you'll want to protect a non-scalable database from being overloaded. One technique is to throttle the database writes using a queue. That way, your highly scalable Lambda component writes to an SQS queue at any rate, and a non-scalable process like a single thread in an EC2 instance reads from the queue at a non-scalable rate and writes to the database at that same, controlled rate. This can help you not overload a non-scalable relational database in RDS, or let you use DynamoDB Provisioned Mode, which is much cheaper than On Demand Mode but takes a couple of minutes to scale.
Multi-Region Architectures in AWS
When I mentioned AWS's definition of High Availability, I always talked about Multi-AZ. Multi-region follows the same idea: Keep your application running if an entire AWS region fails. It's treated as a separate topic for two important reasons: An entire region failing is much less likely than a single resource or an entire AZ failing, and multi-region architectures are much more complex to design and implement, and more expensive to run.
Just like there are Zonal and Regional services, there are a few Global services, such as IAM, Amazon CloudFront and Route 53. However, most of the services that we use for a highly available regional architecture don't support multi-region out of the box. For example, S3 buckets are regional (they exist in a single region), and to make our bucket multi-region we need to create a second bucket in a different region and set up a replication rule. Some other services like Aurora and DynamoDB let you create a Global Database, but even then there are lots of details to consider.
Multi-Region architectures are typically the result of implementing Disaster Recovery Strategies, so I'll refer you to that article and to Data Loss, Replication and Disaster Recovery on AWS.
Conclusion
High availability is the ability of a system to keep working with little or no interruption when one component fails. Specifically for Amazon Web Services, AWS High Availability means to keep working when an Availability Zone fails.
Scalability means changing the capacity to adapt to variations in traffic. It can be vertical (changing the size of existing resource) or horizontal (adding or removing resources). Prefer horizontal scaling, and be eager when scaling out and conservative when scaling in.
For either of them, your deployment units need to be stateless, meaning state (information that is used for more than one request) is stored somewhere else. In practice that means don't install Postgres in the EC2 instance that runs your code.
High availability and scalability are widely accepted as best practices because they're usually easy enough to achieve, unless you didn't make your application stateless, which you should have. If you're consulting, you'll see a lot of companies that don't make apps stateless, and you'll help them improve that. In practice traffic is very rarely guaranteed to be constant, unless you make it so, e.g. via rate limiting or throttling.
The key point of this entire article, which for some reason I needed over 4300 words to say, is: Understand how every service is deployed and how it scales (even for those you have no control over), and architect your solutions based on that, on how much they cost, on what your actual business requirements, and on what your real users actually care about.