- Simple AWS
- Posts
- DynamoDB Database Design
DynamoDB Database Design
Understanding how to design your data in DynamoDB
Guille Ojeda
April 26, 2023
Let's say we're building an e-commerce app, with ECS for the backend, Cognito to secure endpoints, a Code* CI/CD pipeline, and DynamoDB for the database. You already know how to build all of that (if not, check the links!). The problem we're tackling in this article is how to structure the data in DynamoDB.
Here's how our e-commerce app works: A customer visits the website, browses different products, picks some of them and places an order. That customer can apply a discount code (discounts a % of the total) or gift card (discounts a fixed amount) and pay for the remaining amount by credit card.
We're going to use DynamoDB, a fully managed NoSQL database. Here's the trick: NoSQL doesn't mean non-relational (or non-ACID-compliant, for that matter).
Understanding the Data
First, we're going to understand the data that we'll be saving to the database. We're focusing on the entities, not the specific fields that an entity might have, such as Date for the Order. However, in order to discover all entities, you might want to add some fields. We'll represent the entities in an Entity Relation Diagram (ERD).
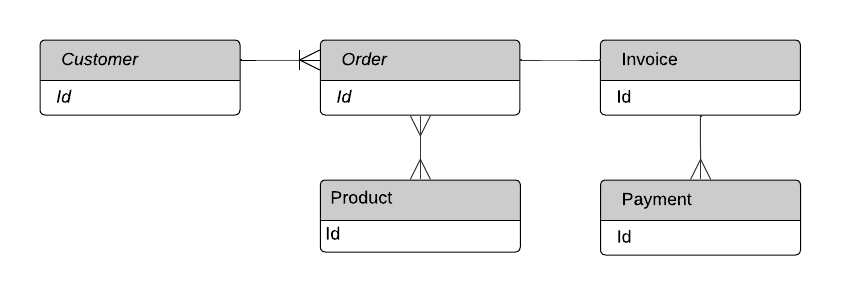
ERD for our e-commerce app
Next, we'll consider how we're going to access the data. We need to define our access patterns, since they're going to determine our structure. This is what the access patterns look like for our example.
Get customer for a given customerId
Get product for a given productId
Get order for a given orderId
Get all products for a given orderId
Get invoice for a given orderId
Get all orders for a given productId for a given date range
Get invoice for a given invoiceId
Get all payments for a given invoiceId
Get all invoices for a given customerId for a given date range
Get all products ordered by a given customerId for a given date range
Implementing Access Patterns for DynamoDB
Next, we're going to implement an example of each access pattern. This is going to determine how we write our data, and how we query it.
To follow along this part, you can use NoSQL Workbench and import the models for every step, or just watch the screenshots.
0 - Create a table
If you're working directly on DynamoDB, just create a table with a PK and SK.
If you're using NoSQL Workbench, use model ECommerce-0.json

1 - Get customer for a given customerId
This one is pretty simple. We're just going to store our customers with PK=customerId and SK=customerId, and retrieve them with a simple query. Since we're going to add multiple entities to our table, we'll make sure the Customer ID is "c#" followed by a number. We're also going to add an attribute called EntityType, with value "customer".
Use model ECommerce-1.json for this step. An example query would be PK="c#12345" and SK="c#12345"

Get customer for a given customerId
2 - Get product for a given productId
Another simple one. We're introducing another entity to our model: Product. We'll store it in the same way, PK=productId and SK=productId, but the value for attribute EntityType is going to be "product". Product ID will start with "p#".
Use model ECommerce-2.json for this step. An example query would be PK="p#12345" and SK="p#12345"

Get product for a given productId
Let's add a bit more data
Use model ECommerce-moredata.json for this step.

Let's add a bit more data
3 - Get all order details for a given orderId and 4 - Get all products for a given orderId
Here we're introducing two new entities: Order and OrderItem. The Order makes sense as a separate entity, so it gets an Order ID starting with "o#". The OrderItem has no reason to exist without an order, and won't ever be queried separately, so we don't need an OrderItemID.
Another big difference is that our Partition Key and Sort Key won't be the same value. An OrderItem is just the intersection of Order and Product, so when we're querying all Products for a given Order, we're going to use PK=orderId and SK=productId, and the attributes for that combination are going to be the quantity and price of the OrderItem.
Use model ECommerce-3-4.json for this step. An example query for 3 - Get all order details for a given orderId would be PK="o#12345". An example query for 4 - Get all products for a given orderId would be PK="o#12345" and SK begins_with "p#"

Get all order details for a given orderId and Get all products for a given orderId
5 - Get invoice for a given orderId
Now we're adding the Invoice entity, which will have an Invoice ID starting with "i#". Notice that there's no reason for us to make the Invoice ID a Partition Key, since the only access pattern we have for Invoices (so far) is getting the Invoice for a given Order.
Use model ECommerce-5.json for this step. An example query would be PK="o#12345" and SK begins_with "i#"

Get invoice for a given orderId
6 - Get all orders for a given productId for a given date range
Querying a DynamoDB table on an attribute that's neither a PK nor an SK is extremely slow and expensive, since DynamoDB scans every single item in the table. To solve queries of the type "for a given range", we need to make that attribute into a Sort Key.
If all we're changing is the SK, then we can use a Local Secondary Index (LSI). In this particular case, since we don't have a way to query by Product ID where we can get the Orders of that Product (i.e. there's no item where productId is the PK and the Order data is in the Attributes), we're going to need to create a Global Secondary Index (GSI).
Could we do this directly on our main table? Yes, we could, but we'd be duplicating the data. So instead we use a GSI which projects the existing data.
You can read more on LSIs and GSIs on our previous Simple AWS issue on DynamoDB.
Use model ECommerce-6.json for this step. An example query would be (on GSI1): PK="p#99887" and SK between "2023-04-25T00:00:00" and "2023-04-25T23:59:00"

Get all orders for a given productId for a given date range
7 - Get invoice for a given invoiceId and 8 - Get all payments for a given invoiceId
We're in the same situation as above: Invoice ID is not a PK, and we need to query by it. We're going to be adding a new element to GSI1, where Invoice ID is the PK and SK.
Notice that we're adding the Payments entity, but only as a JSON object, since we're not going to run any queries on Payments. A potential query would be how much was paid using gift cards, but that's not in our list of access patterns. If something like that comes up in the future, we'll deal with it in the future.
Use model ECommerce-7-8.json for this step. An example query for both access patterns would be PK="i#55443" and SK="i#55443"

Get invoice for a given invoiceId and Get all payments for a given invoiceId
9 - Get all invoices for a given customerId for a given date range and 10 - Get all products ordered by a given customerId for a given date range
So far, our queries have been "for a given Product/Order/Invoice", but we haven't done any queries "for a given Customer". Now that we need Customer ID as a Partition Key, we need to add another GSI. Each of these two access patterns is going to need a different Sort Key, but they both have the same structure: "i#date" and "p#date" respectively. "i#date" means the date of the invoice, while "p#date" means the date of the order where that product appears (which may or may not be the same date). This way we can easily sort by date and grab only a window (a date range), without having to Scan the table.
Use model ECommerce-9-10.json for this step. An example query for 9 - Get all invoices for a given customerId for a given date range would be PK="c#12345" and SK between "i#2023-04-15" and "i#2023-04-30". An example query for 10 - Get all products ordered by a given customerId for a given date range would be PK="c#12345" and SK between "p#2023-04-15" and "p#2023-04-30"

Get all invoices for a given customerId for a given date range and Get all products ordered by a given customerId for a given date range
Final Design for DynamoDB
This is what the final solution looks like

Final solution: main table

Final solution: GSI1

Final solution: GSI2
And these are our access patterns

Access patterns
How to Design Data for DynamoDB
Let's do this section Q&A style, where my imaginary version of you asks questions in italics and I answer them. As always, if the real version of you has any questions, feel free to ask for real!
Why use only one table instead of multiple ones?
Because our data is part of the same data set. The concept of Table in DynamoDB is comparable to the concept of Database in engines like Postgres or MySQL. If the data is related, and we need to query it together, it goes into the same DynamoDB Table.
If we were building microservices, each microservice would have its own Table, because it has its own data.
What are Local Secondary Indices and Global Secondary Indices in DynamoDB?
They're data structures that contain a subset of attributes from a table, and a different Primary Key. Local Secondary Indexes have the same Partition Key and a different Sort Key, while Global Secondary Indexes have a different Partition Key and Sort Key. You define the attributes that you want to project into the index, and DynamoDB copies these attributes into the index, along with the primary key attributes from the base table. You can then query or scan the index just as you would query or scan a table.
Queries against the Primary Key are really fast and cheap, and queries that are not against the Primary Key are really slow and expensive. Indices give us a different Primary Key for the same attributes, so we can query the same data in different ways.
If we're mixing entities as PK and SK, why are we separating some stuff to indices? And why aren't we separating more stuff, or less stuff?
We're not actually storing new data in indices, we're just indexing the same data in a different way, by creating a new Primary Key and projecting the attributes. After step 1 we only had Customer data, then we added support for the access pattern 2 - Get product for a given productId and we had to add new data, so it goes into the base table. When we added support for 6 - Get all orders for a given productId for a given date range we didn't add data, we just needed a new way to query existing data, so we created an index.
In there only one possible design for DynamoDB?
No. And I'm not even sure this is the best design. We could have added Payments as a separate entity with its ID as Partition Key, instead of as a JSON as part of the Invoice. Or added Invoices with InvoiceID as Partition Key to the base table, instead of on a GSI. Both would result in a good design, and while I prefer it this way, I'm sure someone could reasonably argue for another way.
You measure solutions on these two characteristics:
Does it solve all access patterns with indices? If not, add support for all access patterns.
Is it the simplest design you can come up with? If not, simplify it.
If the answer is yes for both questions, it's a good design!
How will this design change over time?
Great question! Database design isn't static, because requirements aren't static. When a new requirement comes up, we need to grow the design to support it (or just use Scan and pay a ton of money). In this example we grew the design organically, tackling each requirement one or two at a time, as if they were coming in every week or few weeks. So, you already know how to do it! Just remember that new data goes into the base table and new ways to query existing data need indices (LSI for a new SK, GSI for a new PK+SK).
If the design depends on the order in which I implement the access patterns, is there anything I can do at the beginning, when I have identified multiple access patterns at the same time?
Yes, there is. Basically, you write down all access patterns, then you eliminate duplicates, then solve each pattern independently on a notebook or Excel sheet (in any order that feels natural), then group up commonalities, and then you simplify the solutions.
I did a bit of it when I grouped up a couple of access patterns and tackled them in one go, or with one index. However, actually showing the whole process would need a much more complex example, and we're already nearing 3000 words on this issue. I'll try to come up with something, possibly a micro course, if anyone's interested.
Is DynamoDB really this complex?
Well, not really. It's not DynamoDB that's complex, it's data management as a whole, regardless of where we're storing it. SQL databases seem simpler because we're more used to them, but in reality you'd have to take that ERD and normalize it to Boyce-Codd Normal Form (I bet you didn't remember that one from college!), then start creating indices, then write complex queries. In DynamoDB all of that is sort of done together with the data, instead of defined separately as the database structure.
Is DynamoDB more complex? Sometimes, though usually it's simpler (once you get used to it). Is it harder? Yes, until you get used to it, which is why I wanted to write this issue. Is it faster? For those access patterns, it's much faster for large datasets. For anything outside those access patterns, it's much slower for any dataset (until you implement the necessary changes).
Best Practices for Amazon DynamoDB
Operational Excellence
Pick the correct read consistency: DynamoDB reads are eventually consistent by default. You can also perform strongly consistent reads, which cost 2x more.
Use transactions when needed: Operations are atomic, but if you need to perform more than one operation atomically, you can use a transaction. Cost is 2x the regular operations.
Monitor and optimize: CloudWatch gives some great insights into how DynamoDB is being used. Use this information to optimize your table.
Security
Use IAM Permissions and least privilege: You need to grant permissions for DynamoDB explicitly, using IAM. You can give your IAM Role permissions on only one table, only for some operations, and you can even do it per item or per attribute. Give the minimum permissions needed, not more.
Reliability
Add an SQS queue to throttle writes: In Provisioned Mode, if you exceed the available Write Capacity Units, your operation will fail. Your backend can retry it, but that increases the response time, and adds even more load to the DynamoDB table. Instead, consider making the write async by pushing all writes to an SQS queue and having a process consume from the SQS queue at a controlled rate. This is especially important when using Lambda functions, since they tend to out-scale DynamoDB Provisioned Mode during big spikes.
Back up your data: You can set up scheduled backups, or do it on-demand. Either way, have backups.
Consider a Global Table: DynamoDB has a feature called Global Table, which is basically a single, global entity that's backed by regular tables in different regions. It's the best option for any kind of multi-region setup, including disaster recovery.
Performance Efficiency
Design partition keys carefully: DynamoDB uses multiple nodes behind the scenes, and the partition key is what determines which node stores what element. If you pick the wrong partition key, most requests will go to the same node, and you'll suffer a performance hit. Pick a partition key that's evenly distributed, such as a random ID. Here's a great read on the topic.
Always query on indexes: When you query on an index, DynamoDB only reads the items that match the query, and only charges you for that. When you query on a non-indexed attribute, DynamoDB scans the entire table and charges you for reading every single item (it filters them afterwards).
Use Query, not Scan: Scan reads the entire table, Query uses an index. Scan should only be used for non-indexed attributes, or to read all items. Don't mix them up.
Use caching: DynamoDB is usually fast enough (if it's not, use DAX). However, ElastiCache can be cheaper for data that's updated infrequently.
Cost Optimization
Don't read the whole item: Read Capacity Units used are based on the amount of data read. Use projection expressions to define which attributes will be retrieved, so you only read the data you need.
Always filter and sort based on the sort key: You can filter and sort based on any attribute. If you do so based on an attribute that's a sort key, DynamoDB uses the index and you only pay for the items read. If you use an attribute that's not a sort key, DynamoDB scans the whole table and charges you for every item on the table. This is independent of whether you query for the partition key or not.
Don't overdo it with secondary indexes: Every time you write to a table, DynamoDB uses additional Write Capacity Units to update that table's indexes, which comes at an additional cost. Create the indexes that you need, but not more.
Use Reserved Capacity: You can reserve capacity units, just like you'd reserve instances in RDS.
Prefer Provisioned mode over On-Demand mode: On-Demand is easier, but over 5x more expensive (without reserved capacity). Provisioned mode usually scales fast enough, try to use it if your traffic doesn't spike that fast.
Consider a Standard-IA table: For most workloads, a standard table is the best choice. But for workloads that are read infrequently, use the Standard-IA table class to reduce costs.
Set a TTL: Some data needs to be stored forever, but some data can be deleted after some time. You can automate this by setting a TTL on each item.
Don't be afraid to use multiple databases: DynamoDB is amazing for simple queries with different parameters, and terrible for complex analytics. Don't be afraid to use a different database for data or use cases that don't fit DynamoDB's strengths.
Did you like this issue? |
Reply