Event-Driven Architecture (EDA) is a software architecture pattern where components communicate via asynchronous events. It's a fantastic solution for decoupling components, but it introduces a lot of complexity into your architecture.
This article is part 2 of a series that will help you understand the Event-Driven Architecture pattern, with two objectives: Understanding why you most likely don't need it, and having fun reading about complex stuff. In this part, we'll focus on the benefits and tradeoffs of Event-Driven Architectures. You can read Part 1: Event-Driven Architecture in AWS: Basic Concepts. Part 3 will be published in the coming weeks.
Drawbacks and Tradeoffs of Event-Driven Architectures
Before we get to the benefits, let's talk about the drawbacks and tradeoffs. Everything in software architecture is a tradeoff, and I don't want you to jump into an event-driven architecture without knowing what you're getting into.
The main drawback here is complexity. I mean, event-driven architectures is a complex enough topic that I'm writing 10k words about it, and I'm barely scratching the surface. But it's not just the complexity of understanding the topic. With event-driven architectures you're splitting everything into services, possibly microservices, and adding complex ways for them to communicate. Sometimes the components are already inherently complex and their communications already happen in complex ways, and we're just changing the mechanism. Other times it's just us adding accidental complexity.
The second big bad thing is the distributed nature of event-driven systems. It means communication is asynchronous, and it can will fail at some point. Instead of BEGIN TRANSACTION; DO 1; DO 2; DO 3; COMMIT TRANSACTION, now every service needs to know the reverse operations to anything that it does, and be listening for when a rollback is required. And what if the message asking for the rollback fails? Or takes too long? Forget about strong consistency, you live in the world of eventual consistency now.
Alright, I've scared you enough. Still with me? Let's see what you can buy for the price of those problems.
Just remember that not all of these benefits might be relevant to you, depending on the business goals for your software. For example, scalability is irrelevant before you even get your first client.
Scalability in Event-Driven Architectures
Scalability is the ability to dynamically change capacity to serve more traffic. Anything that doesn't keep an internal state can be scaled horizontally, which means creating more copies to serve more traffic. If you can run 1 copy, you can run 1.000 copies, possibly each on its own Amazon EC2 instance. But when your entire system is just one "thing" (we call that a monolith), every copy is going to be that entire "thing". Want to scale your payment processing? Well, let's add another copy of your entire system, including payment processing, and also including that recommendation engine that takes up so much memory but is only accessed once a day. If you split your "thing" (monolith) into multiple "things" (much as I love the term "thing", let's start calling them services from now on), now your payment processing service can scale independently of your recommendations service.
Splitting your monolith into services, or even microservices, is the first step towards scaling them independently. However, if your order processing service blocks when it calls payment processing (what we call a synchronous call), then no matter how much you scale payment processing, order processing will always be a bottleneck. Splitting the code and the deployment units isn't enough, we also need to decouple our services. Instead of a synchronous call, we're going to use (you guessed it) an event!
If you want to understand better the difference between a monolithic architecture and an event-driven architecture, check out Monolith vs Event Driven Architecture with an Example.
Is an event-driven architecture just services communicating asynchronously?
Well... Yes! Not any kind of asynchronous communication though, for it to be event-driven those services need to talk to each other using events. And be decoupled. And anyone can listen for any event. Just adding async to a method call doesn't count.
Resilience in Event-Driven Architectures
If you only have one big monolith and it fails, it fails big time. But if your app consists of several services, a failure in one of them doesn't mean all of them fail. Sure, it might mean a whole feature is down, but you can still offer a degraded response (i.e. some features are down, others are working, and you can keep your users happy distracted while you fix things).
For example, if your payment processing service fails, order processing is technically still up, but users won't be able to complete a purchase (at least you won't be able to take their money, which sounds like a pretty important thing to do for a business). They can still view their recommendations though. And if you have a cart, that greatly reduces the user impact of not being able to complete their purchase, since they can save the purchase for later (not ideal, but much better than losing the whole thing and your website showing a 500 error).
Better yet, if you store your events in a queue, your users might not even notice the failure. Your typical flow could be that, after the user inputs their payment data and clicks Purchase, you show them a message saying their order is being processed and they'll get an email once it's completed. The order comes through to your system, OrderProcessing does its thing, and it puts a message in the OrdersReadyForPaymentProcessingQueue. PaymentProcessing reads the message, processes the payment and emits an event that says payment came through for that order. That event will be received by the OrderCompletionNotification service, which notifies the user.
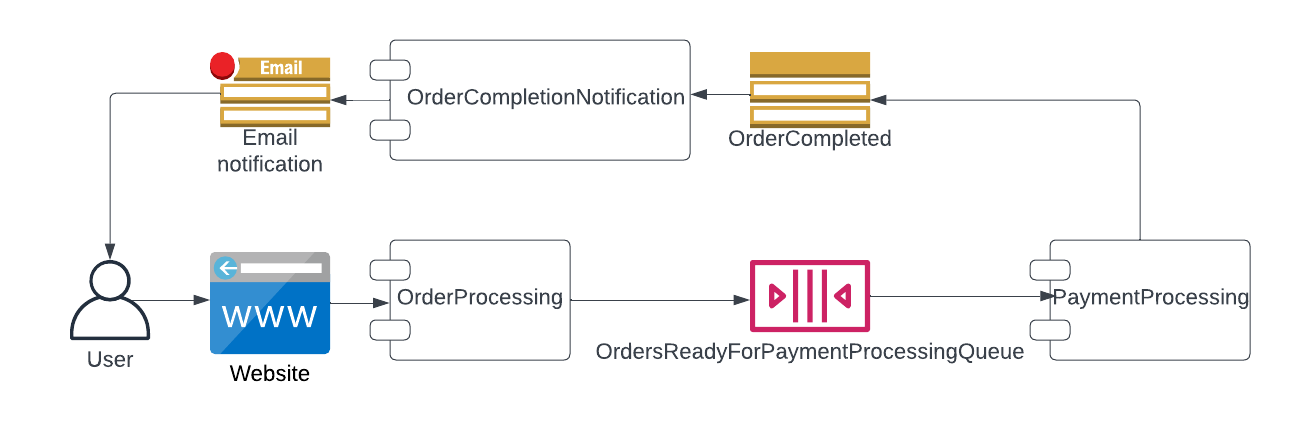
Order processing with an Event-Driven Architecture
This way if PaymentProcessing is down the orders can just sit in the queue while you fix it. A few minutes later, PaymentProcessing comes back up, processes those messages, and the user gets notified that their order has been completed.
What if the fix takes hours instead of minutes? The queue could emit an event when items are taking too long to process or when too many items are queued up, and another service triggered by that event notifies the user about the delay. Users can still make purchases, they just won't complete right now (you could add a banner warning them about that).

More complex order processing with an Event-Driven Architecture
With just a few events here and there, we turned a situation where everything blows up into one where the user doesn't even find out there's a failure that takes down a whole service. That's what we call resilience!
Flexibility in Event-Driven Architectures
In an Event-Driven Architecture you have multiple services which don't know each other, and they only talk through events. That means each service can be whatever the heck it wants, so long as it knows how to read the events that it subscribes to and how to emit events that others can read. You can add a new library, a dependency on an external service, or even have a stub instead of an actual service (which is actually a great technique for developing services quickly). You could even write every service in a different language! In most cases you shouldn't do that though, the cost of maintaining that thing far outweighs the coolness factor.
This is all great, but the real flexibility is in being able to add or remove services without impacting the other services. Already notifying users by email when the order completes, and want to add an in-app notification? Add a new InAppNotification service that's subscribed to the PaymentCompleted topic, and it'll get the same events and can send its notification. You can do that without impacting the other services at all.
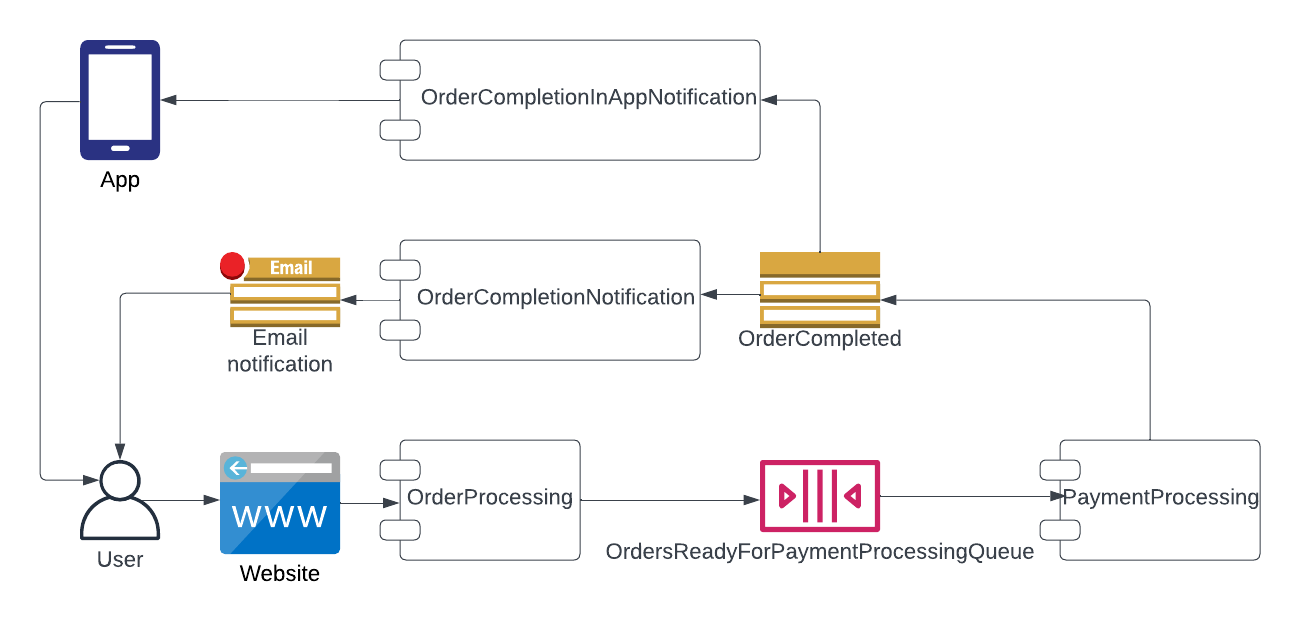
Notifications for order completion with an Event-Driven Architecture
Cost Savings in Event-Driven Architectures
I'll admit this one is mostly clickbait (or eyebait, I guess). But I'll use it to talk about costs, which we definitely care about. An event-driven architecture will allow you to rightsize every service, and scale it to the right level. But all those queues and event buses are not cheap!
The queues and event buses are not the most expensive thing though. The additional maintenance effort derived from the increased complexity in your architecture will result in an increase in maintenance costs that, more often than not, outweighs the potential reduction in operational costs. Translation: EDA is harder, and usually the extra engineers cost you way more than what you might save on your AWS bill.
In some infrequent cases, an event-driven architecture is actually cheaper. In other cases, it's more expensive but the benefits outweigh the extra cost. But in most cases the cost increase is significant, and the benefits are technically there but they don't really make a difference to your application or your business.
Identifying whether an event-driven architecture is a good idea in your situation is part of the architecture design process, which I discussed a bit (though not focused on EDA) in my article about Architecture Concerns for AWS Lambda. The bottom line is that you'll always get the benefits (unless you botch the implementation I guess), and you'll always get the drawbacks and costs. You need to decide if the benefits are more beneficial to you than the costs are costly.
Moreover, while the benefits are technically there, you need to determine whether those benefits are improving a constraint in your system, or they'll be 100% real but still irrelevant. This line of thinking comes from the Theory of Constraints, which states that in any given system there are one or at most a handful of constraints, and that only improvements on the constraints will increase system efficiency.
For example, if your entire order processing workflow takes 5 business days because there's one step that's done manually, implementing an event-driven architecture for the parts that are already automated won't help at all. Furthermore, if the biggest threat to system availability is the one person manually processing payments calling in sick, then making the software part highly available, resilient, fault tolerant, multi-region or whatever keywords you pick won't make a real difference.
Alright, now we know the benefits and we know the drawbacks. When do we get to use event-driven architectures? As a former consultant, I'm tempted to answer "it depends", leave it at that, and send you a 5-figure bill for my services (I'm kidding!). It does depend, but let's shed some light on what it depends on.
Event-Driven Architecture Use Cases
Let's explore a few use cases where benefits of an event-driven architecture usually outweigh the drawbacks, i.e. when using an event-driven architecture is a good idea. We'll analyze them as generic situations or problems, and try to understand why an event-driven architecture is a good idea in these cases.
Complex Event Processing
This one is a bit of a trap: Just because it says "Event" in the name it doesn't mean an Event-Driven Architecture is a good fit. Not every system that processes events needs to be event-driven. I mean, technically every system can be made event-driven. But it's not always a good idea, even if "Event" is in the name.
The scenario that we usually call Complex Event Processing is one where there's at least one event in the system with a complex combination of steps involved in processing it, or a complex set of actions that need to be taken when it happens. "Complex" can mean different things, but think of multiple steps that need to be taken in sequence or in parallel, conditionally, with loops, retry logics, maybe a combination of all of that, and maybe some steps produce outcomes that affect external systems.
For example, when an alert goes off in an IT system, you might want to:
Start tracking the incident, recording events and actions, and annotate everything with timestamps
Start a failover or disaster recovery procedure, like redirecting traffic to another system
Send a notification or an emergency call to whomever is on call
Start an automated recovery process for the failing system
If you're thinking you can solve that with a simple Python script, you're right! But a proper event-processing pipeline will let you perform each of those actions in parallel and in a way that doesn't depend on that script not failing. It lets every part of the system be developed, maintained, updated, run, rerun, retried, and scaled independently.
Alerts for IT systems shouldn't happen that often, so making the response to them more complex doesn't sound like a good way to spend engineering hours (which directly translate to money). However, they're critical enough that it's worth investing in making them resilient. You know what's worse than your system failing? Your system failing and you only hearing about it from your customers.
But what if you had events that happen thousands of times per second? User clickstreams are an example of massive event influx where some steps need to be done real-time, while other steps can be taken either in near-real-time (with a few minutes of delay) or batch processed every few hours. The code and logic for each processing step may not be particularly complex, but the logic of coordinating all the processing steps can get rather complex.
A very relevant aspect is how important are those events. In this case we're talking about user clicks. Do you know what happens if processing fails for one of them? Nothing bad at all, we just get one less click. That means for this particular type of events we're probably good with a Python script. Just keep in mind that the script may fail mid-processing, so the rest of our processes need to be ready for small discrepancies in the numbers: One count might say 100 clicks and the other might say 99. Definitely not something that needs an event-driven architecture.
But what happens if we start talking about a different type of event? Let's forget about clicks per second, and start talking about customer orders. What happens now if we bill UserA for 100 purchases, but only deliver 99? We're in trouble. I bet in this case you'd want that event-driven architecture in place. Notice that we didn't change any numbers here, we just changed the nature of the events. Or rather, we changed how critical the processing of those events is to our system.
Let's change the nature of the events once again. They're still customer orders, but it's a premium subscription to a service. The processing looks like this: The frontend invokes the external payment processor, the payment processor processes the payment and notifies our system, our system sets the attribute IsPremiumUser to true. That's it. Still want an event-driven architecture? I'd say it's probably not worth the trouble. The processing is just as critical as in the previous example, and the throughput could be just as high. However, the processing of the event is so simple (literally just one action in our system: setting an attribute to true) that we don't really need an event-driven architecture.
Summing it up, you likely want an event-driven architecture if the processing of the events is both complex and critical. Throughput usually doesn't matter much, except if it makes another type or architecture fail more often than you can tolerate it (e.g. if the clickstream processing fails 50% of the time because your single EC2 instance can't keep up).
Keep in mind that the processing being complex doesn't just mean there are several steps. Sometimes what's complex is what to do if the processing fails mid-step and you need to retry it and/or revert the previous steps, so you don't get inconsistencies in your data.
Disparate High-Performance Requirements
Truth is, monoliths can and do scale. Facebook does it! And we can also do it, even without the massive engineering knowledge and capacity of Meta. The question is: do we want to?
I'll go ahead and say that in most cases we do. A modular monolith is the best option for most (over 50%) systems. That's my opinion, but it's something I've been saying when talking about microservices and event-driven architecture in the past.
That said, let's focus this part of this article on the cases where we don't want a monolith. The driving force in this case will be the need for the different parts of our system to work at different scales. Let's start with an example.
Consider a security application that scans inbound and outbound emails. Inbound emails need to be scanned for phishing attempts, and that's going to be the job of the InboundEmailScanner module. Outbound emails will be scanned to check whether they are leaking "corporate secrets" to addresses outside the corporate domain, and that will be handled by the OutboundEmailScanner module.
Suppose each module takes an average of 1 second to scan an email. It's safe to assume that as we add the email addresses of employees to the scanner app both modules will need to scale similarly, if we consider that most emails will be to and from an address that's part of the company domain.
But what happens if the company starts sending mass outbound sales emails? Each of those emails will be scanned once as outbound, and since recipients are unlikely to respond (because that's usually the case with cold emails), the amount of inbound emails won't change significantly. Suddenly, the number of emails scanned by the OutboundEmailScanner is much larger than the number scanned by the InboundEmailScanner. This means they need to scale separately. The modules have disparate performance requirements.
That alone is a good indicator that we might want to think about distributed services instead of a monolith. Side note, distributed services doesn't necessarily mean microservices. I've written about monolith vs microservices, but here's the short version:
Monolith: All the code is written together and deployed together.
Modular monolith: The code is separated in modules, everything is deployed together.
Distributed services: The code is separated in services, which are deployed independently.
Microservices: The code and the data are separated in services, which are deployed independently.
Event-Driven Architecture requires either distributed services or microservices, but it doesn't dictate either. It's about how those services communicate with each other, not how the code or data is separated. And since in this example we didn't have any events, let's move on to a slightly more complex example.
In this example we're going to design a stock-trading system. Every second our system is going to receive data from every market that our app integrates with, and it needs to process the data in a complex way: Store it, update graphs, re-calculate market predictions, evaluate "stop losses" (automatically closing positions for users based on a price threshold), generate notifications, and potentially many more things. Each of those processing steps is handled by a different service, and there's one more service: the Trades service, which processes trade requests from users.
Say we launch our stock-trading app with support for only 1 market (New York Stock Exchange) and a maximum of 100 users, and everything works great for us business-wise. As we want to grow, we need to start considering how things will scale. What happens if we add 900 users? The Storage service, the Graphs service and the MarketPredictions service are not going to change, they're still receiving the same amount of data every second. But with 10x users there's also 10x trade operations, 10x open positions to evaluate for stop losses, and 10x people subscribed for notifications. So the StopLosses service, the Notifications service and the Trades service will need to scale 10x.
After a few weeks, we decide to add a new market, the Hong Kong Stock Exchange. Suddenly the Storage, Graphs and MarketPredictions services need to scale 2x. The Trades service probably won't need to scale, since the number of trades a person makes is primarily constrained by the amount of money they have and the amount of time they spend on the app. That also goes for the StopLosses service, if the number of trades doesn't change. The Notifications service is interesting, however, because now users could potentially subscribe to 2x the stocks. It will need to scale to up to 2x, but not immediately.
As you can hopefully see, the problem isn't really that one service handles more traffic than another one right now. The problem is that as our business grows in different ways those services will need to grow at different rates. That's why we want to implement them as distributed services, so we can deploy them, scale them and even re-architect them as needed.
As I mentioned above, we don't need an Event-Driven Architecture pattern to have distributed services. But it does happen to be the best way to communicate distributed services asynchronously, and support complex event processing across distributed services.
System Interoperability
The key term that we need to focus on here is decoupled. Coupling is how much a part of a system has to change if another one changes. With distributed services a service can change how it's implemented and deployed without requiring us to change the services that communicate with it, so in that sense we've achieved loose coupling. But if the service changes its API, services that call it need to adapt to that change.
In an event-driven architecture, a service doesn't need to know how to talk to other services, or who to talk to about a given topic. It just needs to know how to read the events that it's listening for, and emit events that other services can read.
The key here is not that we're making Service A independent of the API of Service B, but rather that we're making Service A independent of the existence of Service B. In an Event Driven Architecture a service doesn't know who receives the events that it sends (called event consumers), or what happens afterwards. It doesn't even know who published the events that it reacts to (called event producers), or what happened before. Its only dependency is to the event bus itself, which is the communication channel (typically a Publish/Subscribe topic) over which it receives events, and to which it publishes events.
Conclusion
The conclusion is that the Event Driven Architecture pattern is complex to implement and maintain. Pulling it off is not exactly the problem, I have absolute faith that you can do it. The problem is that there are other things where your efforts will improve the system more, and generate more money.
I said I have absolute faith in you implementing this, and it's true. But if you still have some doubts, like what happens with transactions that span multiple services (hint: they're called distributed transactions), then you might want to wait for part 3 of this series, coming up in the following weeks.